

No mundo moderno impulsionado pela informação, a capacidade de coletar, processar e analisar grandes volumes de dados em tempo real se tornou um ativo essencial para empresas de todos os setores. É aqui que o Apache Kafka emerge como uma solução inovadora, permitindo o gerenciamento eficiente de fluxos de dados e a criação de uma base sólida para a tomada de decisões estratégicas. Neste artigo, exploraremos o que é o Apache Kafka, como funciona e por que se tornou tão crucial no ecossistema tecnológico atual.
O que é o Apache Kafka?
Desenvolvido pela Apache Software Foundation, o Apache Kafka é uma plataforma de streaming de dados em tempo real que atua como um intermediário entre sistemas de origem e destinos de dados. Sua função principal é a de armazenar, processar e transmitir fluxos contínuos de registros, permitindo que os dados sejam transmitidos e consumidos em tempo real por diferentes partes de um sistema.
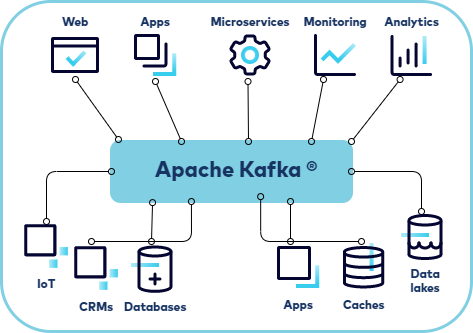
Arquitetura Detalhada do Apache Kafka
O Apache Kafka é baseado em uma arquitetura distribuída que consiste em diversos componentes que trabalham em conjunto para fornecer um ambiente de streaming de dados confiável e escalável.
- Brokers: Os brokers são os servidores onde os dados são armazenados e gerenciados. Cada broker é responsável por uma parte dos dados e particionamento dos tópicos.
- Tópicos e Partições: Os tópicos são canais de dados onde os produtores escrevem e dos quais os consumidores leem. Os tópicos podem ser divididos em partições, permitindo que os dados sejam distribuídos e processados paralelamente.
- Produtores: Os produtores são aplicativos ou sistemas que enviam dados para os tópicos. Eles escolhem em qual tópico enviar a mensagem e, se o tópico estiver particionado, podem especificar a partição.
- Consumidores: Os consumidores se inscrevem em tópicos e lêem os dados. Cada partição de um tópico só pode ser lida por um consumidor de cada vez, mas vários consumidores podem ler partições diferentes do mesmo tópico.
Exemplos de Uso
Vamos explorar exemplos concretos de como o Apache Kafka é utilizado em cenários do mundo real:
- Monitoramento de Logs em Tempo Real: Suponha que você tenha um sistema complexo com vários componentes. Você pode usar o Kafka para coletar e transmitir logs de todos esses componentes em tempo real. Os produtores enviarão logs para um tópico de log e os consumidores processarão esses logs para monitoramento contínuo, detecção de anomalias e solução de problemas imediatos.
- Transmissão de Dados em IoT: Na Internet das Coisas (IoT), milhares de dispositivos podem gerar dados simultaneamente. O Kafka pode ser usado para receber esses dados, armazená-los e transmiti-los para análise em tempo real. Cada dispositivo pode ser um produtor, enviando dados para tópicos específicos, enquanto os consumidores realizam análises e tomam decisões com base nesses dados.
- Processamento de Eventos Financeiros: No setor financeiro, eventos como transações, preços de ações e atualizações de mercado ocorrem em tempo real. O Kafka permite que instituições financeiras transmitam esses eventos para aplicativos de análise, onde podem ser processados para detecção de fraudes, modelagem de risco e tomada de decisões de investimento.
Conclusão
O Apache Kafka não é apenas uma plataforma de streaming de dados, mas sim uma ferramenta fundamental para empresas que buscam aproveitar ao máximo o potencial dos fluxos de dados em tempo real. Com sua arquitetura distribuída e recursos de particionamento, o Kafka oferece escalabilidade e resiliência, tornando-se uma escolha lógica para cenários que vão desde o monitoramento de sistemas até a análise de eventos financeiros. À medida que as empresas continuam a enfrentar um ambiente altamente dinâmico e orientado por dados, o Apache Kafka permanece na vanguarda, capacitando-as a transformar dados brutos em insights valiosos em tempo real.

